„Linguists dig deeper into origins of language“ war 1987 der Titel eines Beitrags im Wissenschaftsteil der New York Times. So wie „Paläontologen ihre Fossilien begutachten“ und „Archäologen antike Steine umdrehen“, bemerkte dessen Autor, dass sich Linguisten nun zur Suche nach den menschlichen Ursprüngen zusammengefunden hätten „mit dem letztlichen Ziel, eine Ursprache zu rekonstruieren, die Muttersprache aller Menschen“.
Dieser Artikel sprach den universellen Reiz menschlicher Vorgeschichte an, obgleich seine Ansprüche nicht völlig zutreffend waren. Die Fachleute haben aber tatsächlich in der sprachlichen Evolutionsgeschichte der zweiten Hälfte des 20. Jahrhunderts „tiefer gegraben“ und „weit reichende“ Genealogien vorgeschlagen, die sich über ausgedehnte Räume und Zeiten erstrecken. Nur wenige waren allerdings dazu bereit, die Behauptung einer ultimativen Ursprache zu vertreten, deren Entstehung vor etwa 50 000 Jahren angenommen wird. Wie menschliche Sprache entstand (und ob dies ein oder mehrmals geschehen ist), wie frühzeitig Sprache strukturiert und angewendet wurde und wie sie sich über die Welt verbreitet und diversifiziert hat sind Fragen, die lange über die weiter gefassten vergleichenden Sprachwissenschaften der späten 1980er und frühen 1990er Jahre schwebten. Durch Zeitungsartikel, Fernsehberichte und interdisziplinäre Auseinandersetzung gestalteten sie sich an der Schnittstelle von fachlichem und allgemeinem Interesse. Von den überzeugten „Langfristlern“ wurde aktiv die Öffentlichkeit gesucht, da sie sich in der von eher vorsichtigen Zielsetzungen beherrschten akademischen Welt marginalisiert fanden.

Abb. 2: Karte von Gray & Atkinson, „Language-tree divergence times support the Anatolian theory of Indo-European origin,“ Nature 426, S. 437. Dies war einer der ersten weithin veröffentlichten Versuche, Berechnungsmethoden von evolutionärer Biologie bis Sprachgeschichtswissenschaft anzuwenden.
Aufbauend auf meinen Promotionsforschungen der aufkommenden historisch-vergleichenden Sprachwissenschaften zwischen 1874 und 1918 analysiere ich diese Entwicklungen in meinem Projekt Big Data and the Reconstruction of Linguistic Prehistory. Das Projekt widmet sich ausführlich den politischen, kulturellen, philosophischen und methodologischen Anteilen tiefensprachlicher Rekonstruktion. Hinsichtlich Politik und Kultur erforsche ich beispielsweise mögliche Korrelationen zwischen den Bezügen auf linguistische Monogenese und dem „Ent-Kalten“ des kalten Krieges. Ich zeige philosophisch und methodologisch, dass die Kontroversen um die vorgeschlagenen Makrofamilien (zum Beispiel „Nostratisch“, „Amerindisch“ und sogar „Proto-World“) Sprachgeschichtswissenschaftler zu einer Neubewertung ihrer wissenschaftlichen Grundlagen veranlasst hat (Abb. 1). Was begründet eine „Vorreiterrolle“ in (vor)geschichtlicher Sprachwissenschaft? Bedeutet Fortschritt, noch größere Rätsel zu lösen oder bestehende Muster mit größerer Genauigkeit beschreiben zu können? Gibt es hier Grenzen des wissenschaftlich Erfahrbaren für die Linguisten? Kann die vergleichende Methode vertrauenswürdige Ergebnisse für jedwede Zeitspanne hervorbringen oder macht die schnelle Veränderung in der Sprache diese für bestimmte Zeiten zunichte? Langfristige Interventionen haben die Debatte um die Natur der Daten und den jeweiligen Wert von quantitativen gegenüber qualitativen Methoden weiter angefacht. In dieser Auseinandersetzung zeichnet sich eine Unterstützung für die Einbeziehung datenintensiver interdisziplinärer Praktiken ab, die sich auch in Fachpublikationen und Hochschulausbildung widerspiegelt (Abb. 2).
Mit dem Projekt wird beabsichtigt, die Vielzahl an aktuellen datengetriebenen Aktivitäten in der vorgeschichtlichen Sprachwissenschaftsforschung zu historisieren, wie etwa beispielgebende Projekte der Evolution of Human Languages Datenbank des Santa Fe Institutes und das Automated Similarity Judgment Program des Max-Planck-Institutes für evolutionäre Anthropologie. Diese werden zurückverfolgt in das späte 19. Jahrhundert zu den Bemühungen, die Methoden vergleichender Sprachgeschichtswissenschaft von der indoeuropäischen Familie zu anderen Familien weltweit zu vereinheitlichen. In der Folge werden die Ursprünge der „Lexikostatistik“ in der amerikanischen linguistischen Anthropologie der 1950er und 1960er Jahre betrachtet und als kritische Korrektur früherer vergleichender Arbeit dargelegt. Es folgt die Beschreibung einer inklusiven nostratischen Phylogenie, die indoeuropäische, altaische, uralische und kartwelische Sprachen in einer sehr breiten genetischen Gliederung verbindet, wie sie von Mitgliedern der „Moskauer Schule“, die sich in der Mitte der 1960er um die Arbeit von Wladislaw Markowitsch Illitsch-Switytsch vereinigte, entwickelt wurde (Abb. 3). In den nordamerikanischen Kontext übergehend werden die Kontroversen um Joseph Greenbergs klassifikatorische Aufarbeitung afrikanischer und amerikanischer Sprachen rekapituliert, unter Verwendung der Methode des „Massen-“ beziehungsweise „multilateralen“ Vergleichs, eine Art Annäherung an Big Data mit Papier und Bleistift. Die Untersuchung endet in der Mitte der 1980er als qualitative sowjetische und quantitative amerikanische Traditionen begannen, ineinander zu fließen. Diese Zusammenarbeit wurde geformt vor dem Hintergrund erhöhter öffentlicher Neugierde in den Wissenschaften zu den menschlichen Ursprüngen, ausgelöst vom Aufkommen der Out-of-Africa-Theorie.
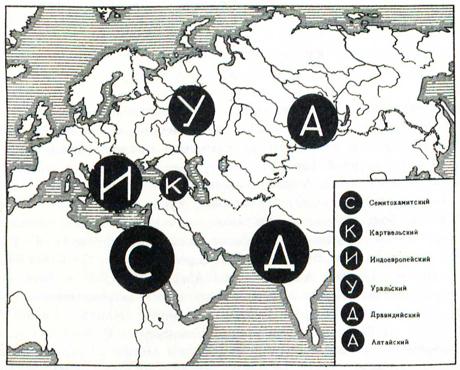
Abb. 3: Karte aus dem ersten Band von Wladislaw Markowitsch Illitsch-Switytsch Wörterbuch des Nostratischen (1971), S. 45. Dies regte Folgeaktivitäten der „Moskauer Schule“ an und ist eines der ersten erhaltenen Arbeiten zu makrokomparativer Linguistik.
Big Data and the Reconstruction of Linguistic Prehistory vertritt die Position, dass die von langfristiger sprachwissenschaftlicher Rekonstruktion erzeugten Kontroversen den Historikern sehr viel über die stillschweigenden Beweis- und Methodenstandards in den Sprachwissenschaften sagen kann. Etwas allgemeiner, bietet das Projekt neuen Aufschluss über Sammlung, Vergleich und Klassifizierung von Big Data über die letzten 150 Jahre hinweg.