Nach der Verbreitung der Drucktechnologie wurden 358 verschiedene Ausgaben mit einer angenommenen Auflage von jeweils rund 1000 Exemplaren produziert, womit zwischen 1472 und 1650 geschätzt 350.000 Bücher in ganz Europa im Umlauf waren. Das Gemeinschaftsprojekt De Sphaera. Knowledge System Evolution and the Shared Scientific Identity of Europe, das mit dem Research IT-Team des MPIWG und dem Berliner Zentrum für maschinelles Lernen entwickelt wurde, nutzt diese spannende Sammlung, um Evolutionsprozesse des Wissens zu untersuchen.

Die Analyse des Korpus zeigt, dass Wissen schrittweise in technischer und materieller Hinsicht umgestaltet wurde. Leser wurden zunehmend aufgefordert zu lernen, wie sie eine eigene Armillarsphäre bauen können, um Sacroboscos Originaltext, der eine qualitative Einführung in die geozentrische Kosmologie darstellt, besser zu verstehen. Mauro da Firenze, Johannes de Sacrobosco, Annotationi sopra la lettione della spera del Sacro Bosco. Dove si dichiarano tutti e principii Mathematici et Naturali, che in quelle si possan desiderare. Firenze: Lorenzo Torrentino, 1550, 96 (hdl.handle.net/21.11103/sphaera.101035).
Unser Repositorium – CorpusTracer – wurde speziell für die Erforschung des kulturellen Erbes entwickelt und umfasst ein breites Spektrum an heterogenen und hochvernetzten Daten. Das De Sphaera-Projekt zielt darauf ab, neue Ansätze einer rechnergestützten Geschichtswissenschaft zu etablieren, bei der die individuelle historische Quellenforschung mit interdisziplinären Untersuchungen unter Einbeziehung der digitalen Geisteswissenschaften, der Datenwissenschaft, der Mathematik komplexer Systeme und des maschinellen Lernens kombiniert wird.

Der Startbildschirm von CorpusTracer enthält ein Suchfeld und zeigt die kürzlich bearbeiteten Buch- und Personendatensätzen. Die Bilder und biografischen Daten der Personen stammen direkt aus Wikidata.
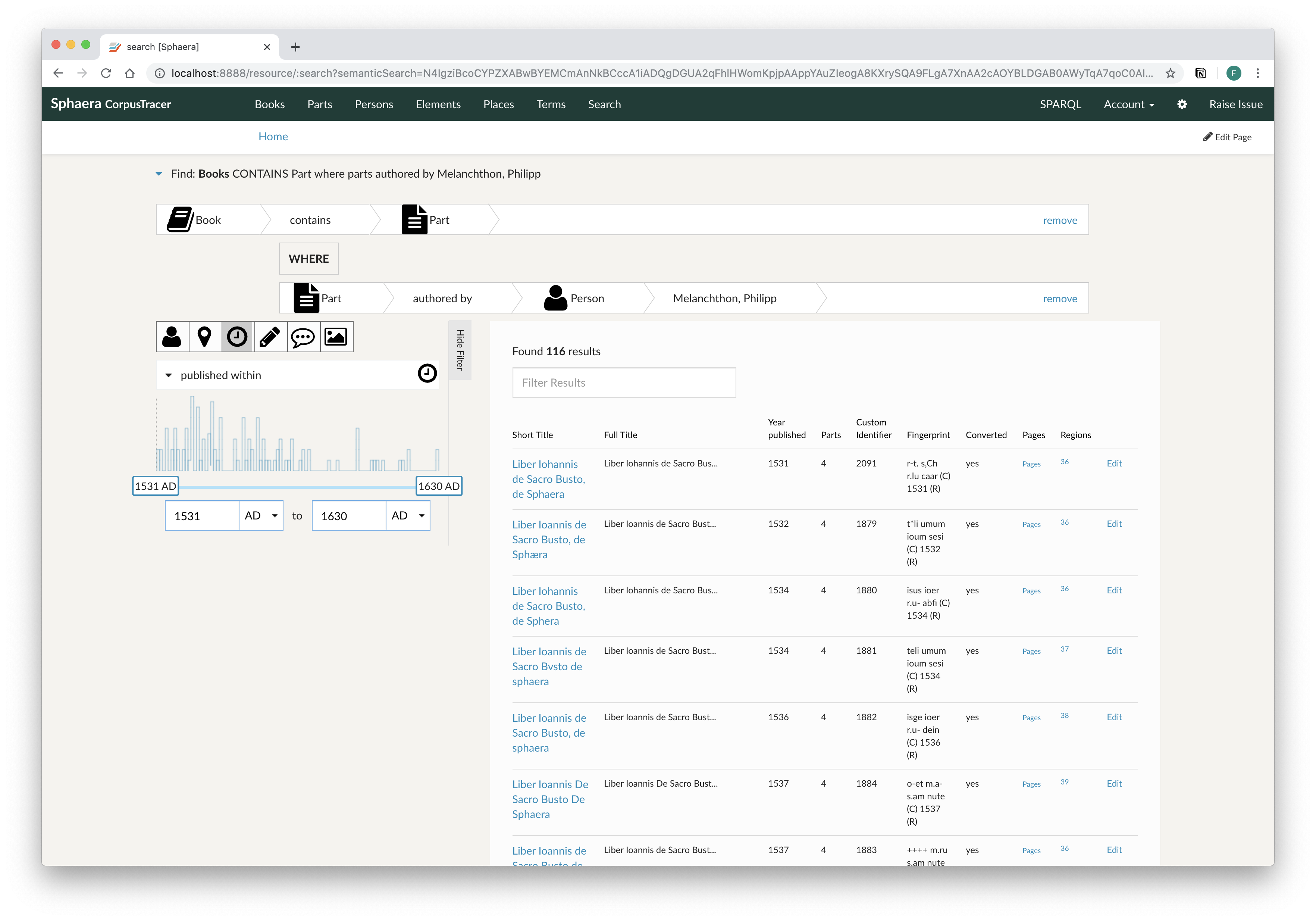
Eine spezialisierte Suchöberfläche ermöglicht es auch ohne genaue Kenntnisse über die Struktur der Daten komplexe Abfragen in der Graph-Datenbank durchzuführen.

Über einen IIIF-kompatiblen Image Viewer kann auf die digitalisierten Seiten jedes Buches zugegriffen Werden. Auf diese Weise können Einzelseiten genau betrachtet und gelesen, sowie Elemente auf der Seite, z. B. Abbildungen, identifiziert und mit Anmerkungen versehen werden.

Zu allen Ausgaben wurden detaillierte bibliografische Daten erfasst, auf die mit der Datenbank zugegriffen werden kann.
Epistemische Gemeinschaften
Seit 2017 wurden in dem De Sphaera-Projekt mit zwei unterschiedlichen Ansätzen die Entstehung und Konsolidierung sowohl sozialer als auch epistemischer Gemeinschaften im frühneuzeitlichen Europa über einen Zeitraum von rund 200 Jahren untersucht. Zunächst untersuchte eine Arbeitsgruppe mit dem Titel The Authors of the Commentaries die Profile und Motive frühneuzeitlicher Kommentatoren von wissenschaftlichen Lehrbüchern. Danach ermöglichte die Fülle der gesammelten Quellendaten – Daten aus wissenschaftlichen Texten, Bildern und Tabellen – eine datenorientierte Analyse, die ergab, dass sich im 16. Jahrhundert epistemische Gemeinschaften etabliert hatten, die prompt das wissenschaftliche Wissen auf dem gesamten Kontinent prägten.

Geographische und zeitliche Verteilung der Produktion der zum Korpus gehörenden Bücher. Die Visualisierung wurde mit Palladio erstellt. Quelle: F. Kräutli.
Was ließ sich daraus ableiten? Wie der Open-Access-Band der Arbeitsgruppe De sphaera of Johannes de Sacrobosco in the Early Modern Period: The Authors of the Commentaries (Springer Nature, 2020) zeigt, waren die Autoren wissenschaftlicher Lehrbuchkommentare ausnahmslos alle stark in das universitäre Geschehen involviert. Durch die zunehmende Integration mathematischer Arbeiten über alle Disziplinen hinweg spiegelt sich in ihren Kommentaren die Erweiterung des spätmittelalterlichen Wissenssystems wider, das bis dahin vor allem durch die Wechselbeziehungen zwischen Kosmologie, Astrologie, Astronomie und Medizin und den Bereichen Geographie, Kosmographie und nautischen Astronomie geprägt war.

Die Verbreitung der Drucktechnologie hat das Wissen des Mittelalters zum ersten Mal erweitert und verbreitet: Von 208 Autoren, die im Korpus identifiziert wurden, lebten nur 58, als die Ausgaben mit ihren Texten veröffentlicht wurden. Nur langsam begannen Drucker und Verleger, zeitgenössische wissenschaftliche Texte zu produzieren. Nur bei 18 Autoren überschneiden sich die Lebenszeiten und das Produktionsjahr des Buches in denen ihre Texte abgedruckt wurden.
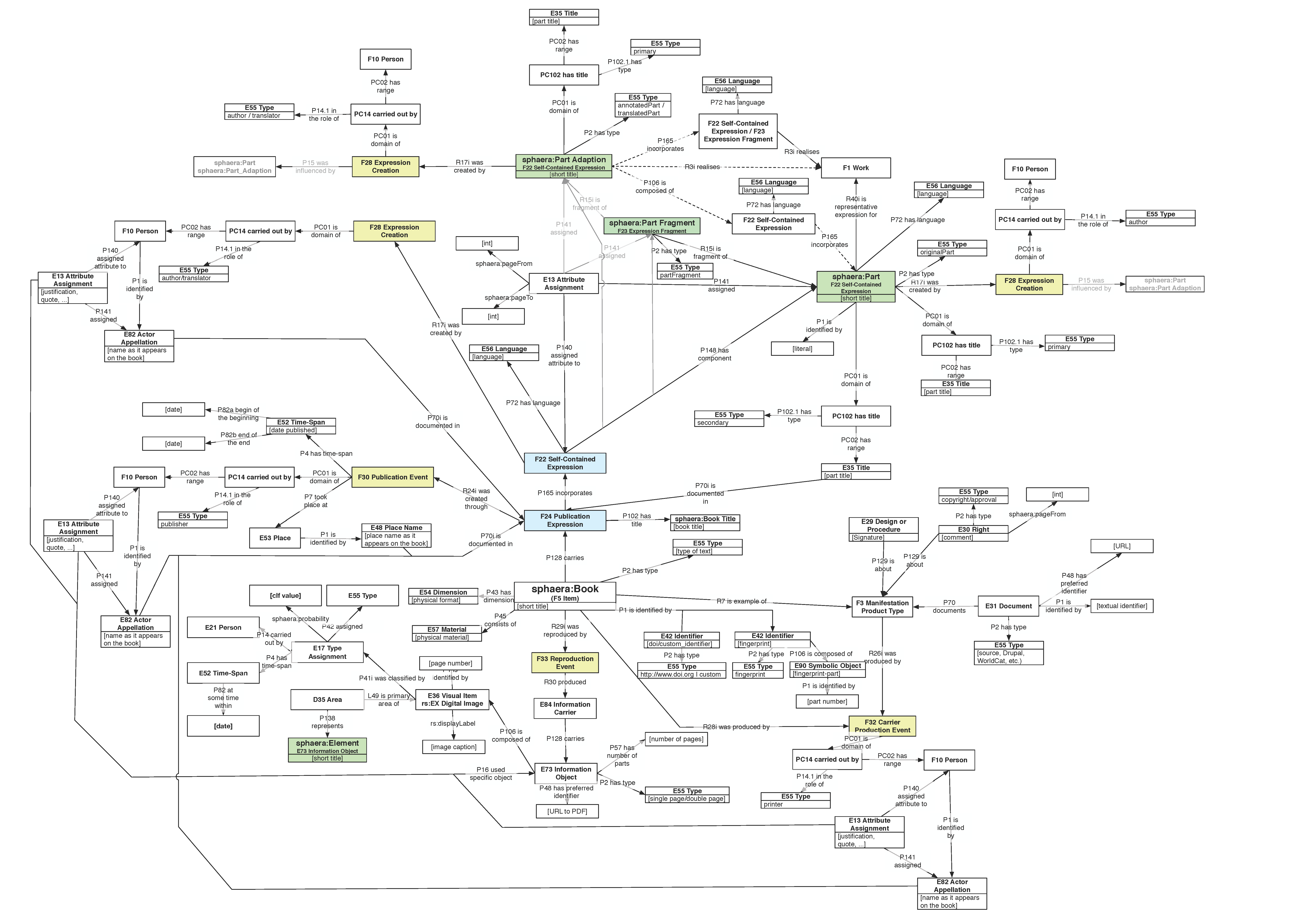
CorpusTracer verwendet ein graphbasiertes Datenmodell, das auf Linked Data und der CIDOC-CRM Ontologie aufbaut. Diese Darstellung zeigt, welche Entitäten in der Datenbank vorhanden sind (Bücher, Personen, Text Parts, Sprachen usw.) und in welcher Beziehung sie zueinander stehen.
Die aus den De sphaera-Quellen extrahierten Daten sollen dazu dienen, die Mechanismen der Produktion von wissenschaftlichen Erkenntnissen aufzuzeigen. Die Abhandlungen wurden in das zerlegt, was wir als „Wissensatome“ definieren. Diese werden über Textabschnitte („Textteile“) und deren Wiederauftreten im gesamten Korpus im Lauf der Zeit ermittelt. Durch Bestimmung dieser Abschnitte als „Originaltexte“, „Paratexte“, „Kommentare“, „Übersetzungen“, „Textfragmente“ und alle daraus möglichen Kombinationen wurden die Daten als Multiplex-Netzwerk mit fünf Ebenen modelliert. Diese wurden dann in Zusammenarbeit mit der Forschungsgruppe Nonlinear Dynamics and Time Series Analysis unter der Leitung von Holger Kantz am Max-Planck-Institut für Physik komplexer Systeme analysiert, und die Ergebnisse wurden unter dem Titel „The Emergence of Epistemic Communities in the Sphaera Corpus: Mechanisms of Knowledge Evolution“ (Journal of Historical Network Research, 2019) im Open Access veröffentlicht. Die Datenanalyse zeigt, wie die Wittenberger Drucker, die im Rahmen der evangelischen Reformation tätig waren, europaweit die Führung bei der Ausrichtung von Inhalt und Format astronomischer Lehrbücher übernehmen konnten.

Visualisierung des Multilayer-Netzwerks mittels muxViz (muxviz.net).
Nächste Schritte: Drucker und Akteure
Da sich die Rolle von Druckern, Verlegern und Buchhändlern für die Gestaltung wissenschaftlicher Unterfangen in der Frühen Neuzeit als absolut entscheidend erwiesen hat, steuert die De Sphaera-Forschung in diese Richtung. Eine neue Arbeitsgruppe – The Printing Press and the European Academic Milieu 1470–1650: Defining Modes of Interaction and Scientific Exchange in the World of Printed Words – soll die wirtschaftlichen und institutionellen Mechanismen des akademischen Buchmarktes in der frühen Neuzeit untersuchen. Ein erstes Treffen von 18 internationalen Wissenschaftlern aus dem Bereich der frühneuzeitlichen Universitäts- und Buchgeschichte, organisiert von Matteo Valleriani und Andrea Ottone vom Projekt The Early Modern Book Trade unter der Leitung von Angela Nuovo, findet Anfang 2020 am Max-Planck-Institut für Wissenschaftsgeschichte statt.
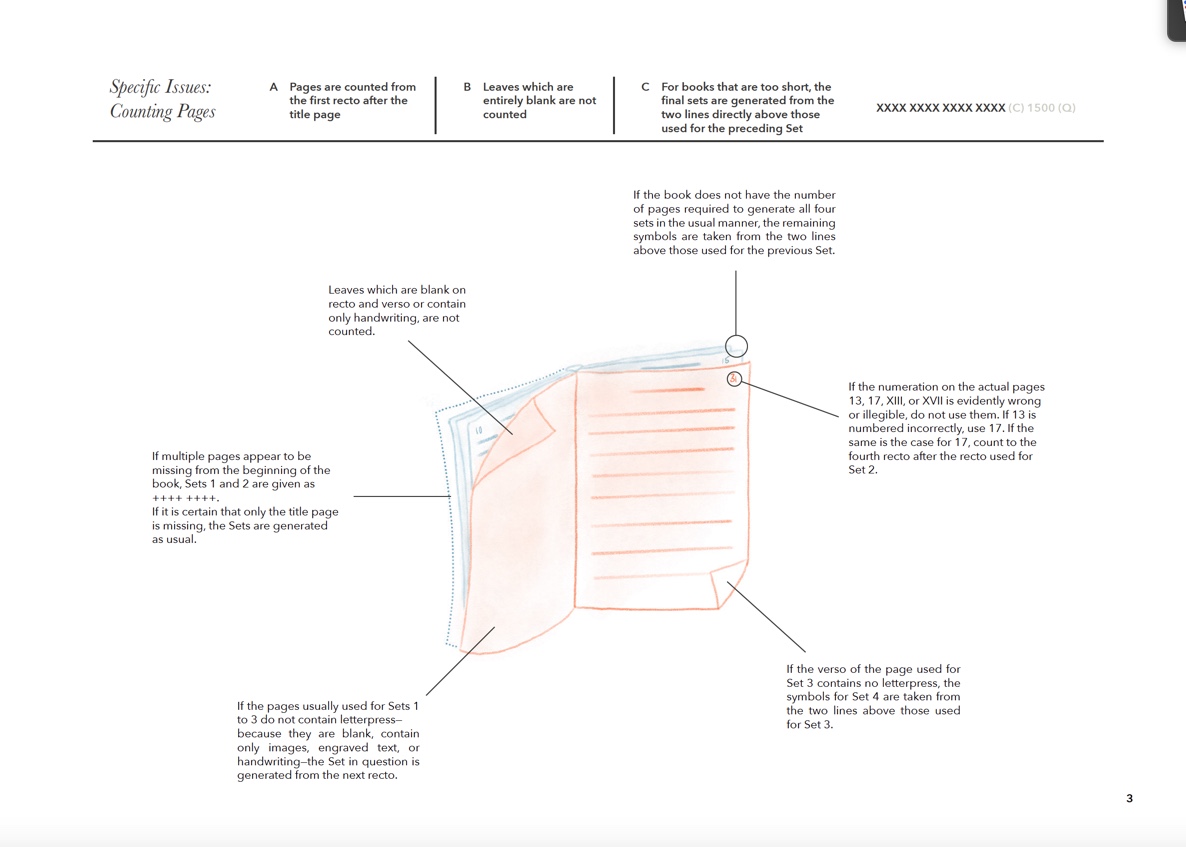
Detail des grafischen Workflows zum Extrahieren von Fingerabdrücken aus Drucken der frühen Neuzeit, um zu erkennen, ob verschiedene Ausgaben oder Teile von Büchern tatsächlich im Rahmen derselben Auflage erstellt wurden.
Ferner wurde ein weiterer Datensatz erstellt, um soziale, institutionelle und wirtschaftliche Beziehungen zwischen den Hauptakteuren abzubilden, die hinter der Produktion der untersuchten Abhandlungen stehen: Drucker, Verleger und Autoren, die auch an der Universität unterrichteten. Zur Realisierung dieses Datensatzes wurden Fingerprints von den Abhandlungen extrahiert – d. h. von den materiellen Buchexemplaren extrahierte Daten, die die Identifizierung und den Vergleich ohne Bezug zu den bibliographischen Metadaten der Bücher ermöglichen. Dadurch lassen sich Publikationen mit ähnlichem oder identischem Inhalt und gleicher materieller Zusammensetzung erkennen, z. B. wenn diese zur gleichen Auflage gehören, obwohl sie von verschiedenen Druckern mit unterschiedlichen Titelblättern verkauft wurden. Das ursprünglich von der EDIT 16 Datenbank entwickelte Verfahren zur Fingerprint-Extraktion wurde weiterentwickelt, und es entstand das Handbuch How to Generate a Fingerprint von Victoria Beyer. Das ultimative Ziel dieses Vorhabens ist es, statistische Zusammenhänge zwischen inhaltsorientierten Datensätzen und Sozialdatensätzen zu analysieren, um die Beziehungen zwischen der Entstehung epistemischer Gemeinschaften und dem gesellschaftlichen Verhalten der beteiligten Akteure zu ermitteln.

Mit Hilfe von Computer Vision und Visulisierungstools können ähnliche Abbildungen in unserem Korpus identifiziert werden. Zwei existierende Visualisierungstools wurden zu diesem Zweck verwendet und angepasst: COINS, welches von Flavio Gortana zur Visualisierung einer numismatischen Sammlung entwickelt wurde, und VIKUSViewer, ein generisches Visualisierungstool für kulturelle Sammlungen, entwickelt von Christopher Pietsch. Quelle: F. Kräutli.
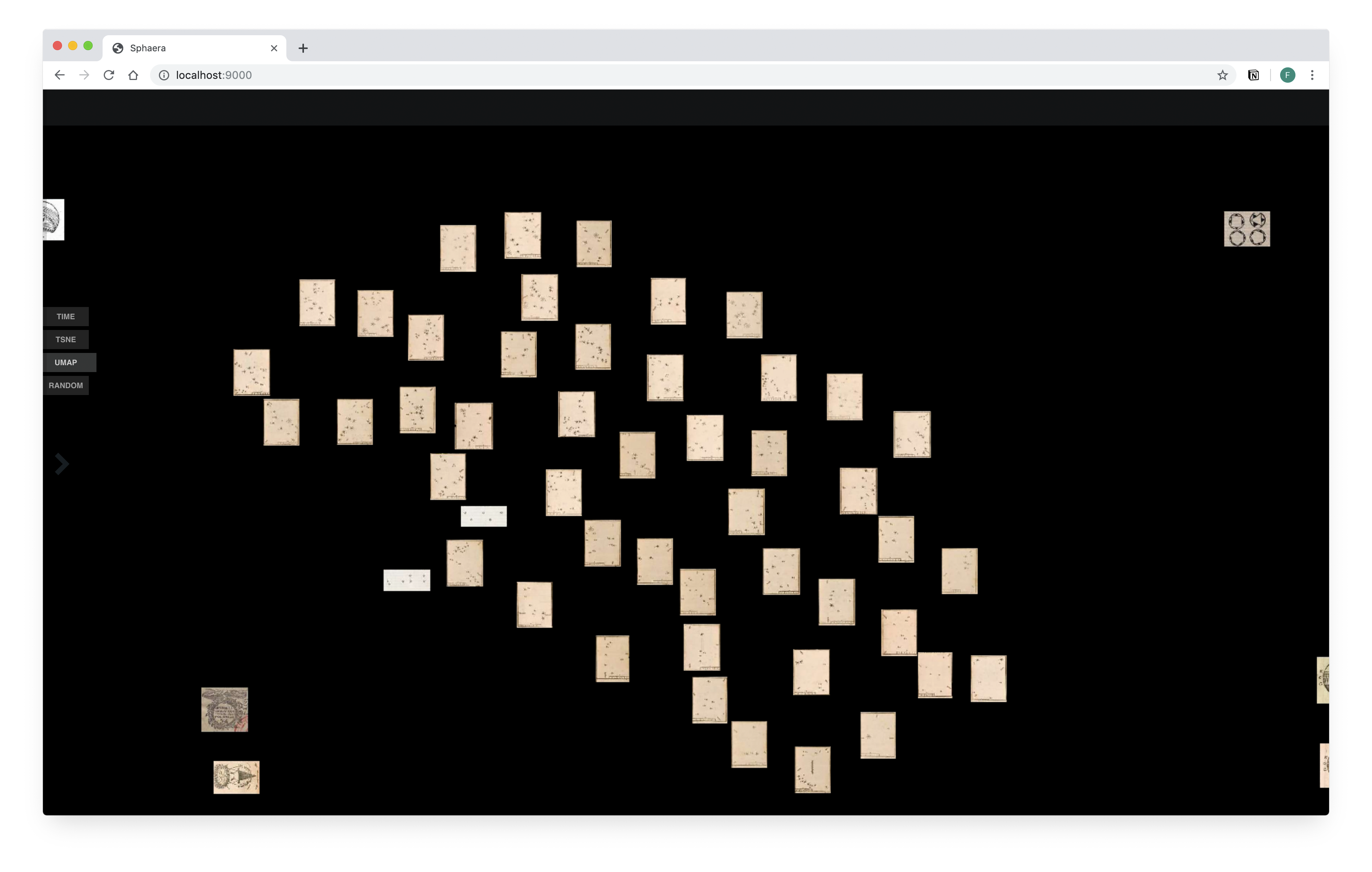
Eine Gruppe ähnlicher, aber nicht identischer Illustrationen im Sphaera Korpus. Wir identifizieren diese, indem wir Feature Vektoren der Bilder aus einem Convolutional Neural Network gruppieren. Die Gruppen enthalten neben Drucken aus dem gleichen Holzschnitt auch solche, die als Kopien einer existierenden Abbildung neu geschnitzt wurden. Im letzteren Fall können wir davon ausgehen, dass der durch Kopie darzustellende Inhalt demjenigen der Originalillustration ähnlich ist. Auf diese Weise erhalten wir Gruppen von "semantisch ähnlichen" Abbildungen.
Höher hinaus: Das Berliner Zentrum für maschinelles Lernen
Neben den aus den Textquellen extrahierten Daten konzentrierte sich das Projekt auch auf andere Wissensträger: Im Rahmen des Berliner Zentrums für maschinelles Lernen wurden Algorithmen zur automatischen Identifizierung und Extraktion von Abbildungen und Tabellen aus historischen Quellen entwickelt. Daraus entstand ein Korpus von rund 29.500 Bildern – 21.000 Inhaltsillustrationen, dazu Initialen, Titelblätter, Frontispize, Dekorationen und Druckermarken – und 8.000 astronomischen Tabellen. Unsere aktuelle und zukünftige Arbeit beinhaltet die Entwicklung einer Reihe von Algorithmen zur Gruppierung dieser Daten nach Ähnlichkeiten, die in Abhängigkeit von den historischen Forschungsfragen definiert werden. Unser ultimatives Ziel ist es, das Wissensnetzwerk durch neue Graphen zu bereichern, die die Gesamtheit der Inhalte der historischen Quellen repräsentieren, um dann die Möglichkeit zu erforschen, das Netzwerk in seiner Gesamtheit zu modellieren und um die Evolution des Wissens mit anderen Evolutionsprozessen vergleichen zu können, wie sie beispielsweise im Rahmen der Evolutionsbiologie beschrieben wurden.

Eine Gruppe ähnlicher, aber nicht identischer Illustrationen im Sphaera Korpus. Wir identifizieren diese, indem wir Feature Vektoren der Bilder aus einem Convolutional Neural Network gruppieren. Die Gruppen enthalten neben Drucken aus dem gleichen Holzschnitt auch solche, die als Kopien einer existierenden Abbildung neu geschnitzt wurden. Im letzteren Fall können wir davon ausgehen, dass der durch Kopie darzustellende Inhalt demjenigen der Originalillustration ähnlich ist. Auf diese Weise erhalten wir Gruppen von "semantisch ähnlichen" Abbildungen.
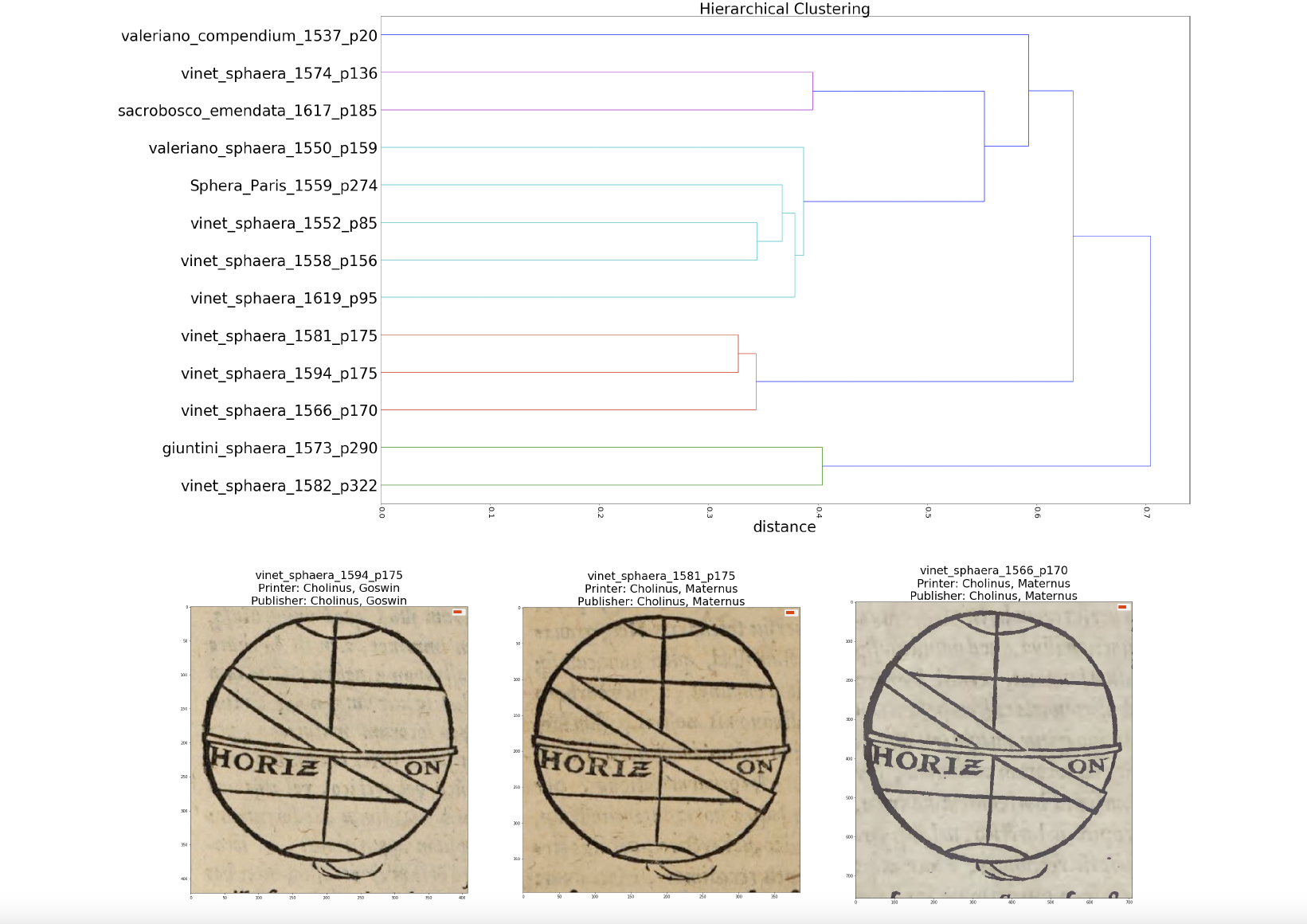
Wir quantifizieren die Ähnlichkeiten zwischen den Elementen in einer Gruppe semantisch ähnlicher Abbildungen weiter, indem wir ein numerisches Mass für Ähnlichkeit aus dem Bereich der Computer Vision anwenden. Anhand dieses Ähnlichkeitsmaßes können wir Abbildungen unterscheiden, die aus Drucken mit demselben Holzschnitt stammen. Oben: Dendrogramm der hierarchischen Gruppierung der Elemente einer der Gruppen semantisch ähnlicher Abbildungen: Unten: Eine der durch diese Gruppierung erzeugte Untergruppen. Die Information, dass derselbe Holzschnitt für den Druck dieser Illustrationen verwendet wurde, wird kontextualisiert, indem sie mit Metadaten korreliert wird, wodurch kontextbezogene Rückschlüsse möglich werden. Das vorliegende Beispiel zeigt, dass Goswin Cholinius die Druckerei seines Vaters Maternus weiter betrieben hat.